Алгоритм Дейкстры
Расстояние от s до s, конечно же, равно 0. Кроме того, это расстояние уже никогда не сможет стать меньше - ведь веса всех ребер графа у нас положительны. Таким образом:
dist[s]:= 0; done[s]:= true; last:= s;
Повторить N-1 раз следующие действия:
для всех непомеченных вершин х, связанных ребром с вершиной last, необходимо пересчитать расстояние:
dist[x]:= min(dist[x], dist[last]+ sm[last,x]);среди всех непомеченных вершин найти минимум в массиве dist: это будет новая вершина last;пометить эту новую вершину в массиве done.
Алгоритм Infix
Если не достигнут конец строки ввода, прочитать очередной символ.
Если этот символ - открывающая скобка, то:
создать новую вершину дерева;вызвать алгоритм Infix для ее левого поддерева;прочитать символ операции и занести его в текущую вершину;вызвать алгоритм Infix для правого поддерева;прочитать символ закрывающей скобки (и ничего с ним не делать).
Иначе:
создать новую вершину дерева;занести в нее этот символ.
Алгоритм Каркас-Рек
Этот алгоритм базируется на прямом обходе графа, который учитывает два условия: во-первых, чтобы суммарный вес текущего каркаса был меньше текущего минимума и, во-вторых, чтобы в каркасе было ровно N-1 ребро1) (N - количество вершин графа).
Алгоритм КомпСвяз-Итер
Прочитать начало и конец очередного ребра. Далее возможны 4 различные ситуации:
Оба конца ребра еще не относятся ни к одной из ранее встретившихся компонент связности (mark[u]=0 и mark[v]=0). В этом случае количество компонент связности kol увеличивается на единицу, а новая компонента связности получает очередной номер ks+1.Один конец ребра уже относится к какой-то компоненте связности, а второй - еще нет (mark[u]=0, а mark[v]<>0). В этом случае общее количество компонент связности kol остается прежним, а непомеченный конец ребра получает ту же пометку, что и второй его конец.Оба конца нового ребра относятся к одной и той же компоненте связности (mark[u]= mark[v]<>0). В этом случае не нужно производить никаких действий.Концы нового ребра относятся к разным компонентам связности (0

По окончании работы этого алгоритма в массиве mark будет записано S различных целых чисел, каждое из которых будет означать отдельную компоненту связности. Кроме того, в массиве могут остаться нулевые компоненты: каждая из них будет соответствовать изолированной вершине, которая тоже является отдельной компонентой связности. Следовательно, количество нулей должно быть прибавлено к количеству компонент, найденному в процессе работы основного алгоритма.
Алгоритм КомпСвяз-Рек
Совершить обход в глубину всех компонент связности графа, помечая вершины каждой из них отдельным номером.
Рекурсивная процедура обхода в глубину (прямого или обратного обхода) переберет все вершины, достижимые из начальной. Начальной вершиной для очередной компоненты связности может стать любая вершина, еще не отнесенная ни к какой другой компоненте связности (то есть еще не помеченная в массиве mark).
По окончании работы программы переменная kol будет содержать количество найденных компонент связности.
Алгоритм Краскала
Упорядочить все ребра графа по возрастанию их весов.Применить алгоритм КомпСвяз-Итер (см. пункт "Подсчет количества компонент связности").
Замечание: Выполнение алгоритма Краскала можно завершить сразу же, как только в каркас будет добавлено (N-1)-е ребро (поскольку в дереве с N вершинами должно быть ровно N-1 ребро).
Алгоритм Postfix
Если не достигнут конец строки ввода, прочитать очередной символ,если этот символ - операнд, то занести его в стек1),иначе (символ - операция): создать новый элемент, записать в него эту операцию;достать из стека два верхних (последних) элемента, присоединить их в качестве левого и правого операндов в новый элемент;занести полученный "треугольник" в стек.
По окончании работы этого алгоритма в стеке будет содержаться ровно один элемент - указатель на корень построенного дерева.
Алгоритм PostOrder
Начать с корня дерева.Совершить обратный обход левого поддерева.Совершить обратный обход правого поддерева.Пометить текущую вершину.
Замечание: Этот алгоритм также может быть распространен на случай произвольного корневого дерева.
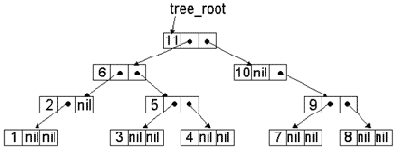
Рис. 12.3. Последовательность нумерации вершин при обратном обходе дерева
Алгоритм Prefix
Если не достигнут конец строки ввода, прочитать очередной символ.Создать новую вершину дерева, записать в нее этот символ.Если символ - операция, то: вызвать алгоритм Prefix для левого поддерева;вызвать алгоритм Prefix для правого поддерева.
Алгоритм PreOrder
Начать с корня дерева.Пометить3) текущую вершину.Совершить прямой обход левого поддерева.Совершить прямой обход правого поддерева.
Замечание: Этот алгоритм может быть естественным образом распространен и на случай произвольного корневого дерева.
Алгоритм Расст-Рек
Совершить обход графа в глубину, при каждом "шаге вперед" прибавляя длину ребра к длине текущего пути, при каждом возврате - отнимая длину этого ребра от длины текущего пути. При движении "вперед" пометки посещенности вершин ставятся, при "откате" - снимаются. По достижении выделенной вершины t производится сравнение длины текущего пути с ранее найденным минимумом.
Алгоритм SyntOrder
Начать с корня дерева.Совершить прямой обход левого поддерева.Пометить текущую вершину.Совершить прямой обход правого поддерева.
Замечание: Этот обход специфичен только для бинарных деревьев, поэтому невозможно применить его к произвольному графу, каркасом которого совершенно не обязательно будет именно бинарное дерево.
Алгоритм TreeSort
Для сортируемого множества элементов построить дерево двоичного поиска: первый элемент занести в корень дерева;для всех остальных элементов: начать проверку с корня; двигаться влево или вправо (в зависимости от результата сравнения с текущей вершиной дерева) до тех пор, пока не встретится такой же элемент, либо пока не встретится nil. Во втором случае нужно создать новый лист в дереве, куда и будет записано значение нового элемента.Совершить синтаксический обход построенного дерева, печатая каждую встреченную вершину столько раз, сколько было ее вхождений в сортируемый набор.
Алгоритм WideOrder
Занести в очередь1) корень дерева.Пока очередь не станет пустой, повторять следующие действия: удалить первый элемент из головы очереди;добавить в хвост очереди всех потомков удаленной вершины.
Древесная сортировка
Задача. Упорядочить заданный набор (возможно, с повторениями) некоторых элементов (чисел, слов, т.п.).
Другие названия
Префиксный обход: результатом прямого обхода2) дерева синтаксического анализа арифметического выражения будет префиксный вариант записи этого выражения.
Обход в глубину "сверху вниз": название имеет смысл лишь в случае стандартного расположения дерева корнем кверху.
Другие названия
Постфиксный обход: результатом обратного обхода ДСА арифметического выражения будет постфиксный вариант записи этого выражения.
Обход в глубину "снизу вверх": название имеет смысл лишь в случае стандартного расположения дерева корнем кверху.
Другие названия
Инфиксный обход: результатом синтаксического обхода ДСА арифметического выражения будет инфиксный вариант записи этого выражения.
Обход "слева направо": название имеет смысл лишь в случае стандартного расположения дерева корнем кверху.
Другие названия
Префиксный обход: результатом прямого обхода3) дерева синтаксического анализа арифметического выражения будет префиксный вариант записи этого выражения.
Обход в глубину "сверху вниз": название имеет смысл лишь в случае стандартного расположения дерева корнем кверху.
Другие названия
Постфиксный обход: результатом обратного обхода ДСА арифметического выражения будет постфиксный вариант записи этого выражения.
Обход в глубину "снизу вверх": название имеет смысл лишь в случае стандартного расположения дерева корнем кверху.
Другие названия
Инфиксный обход: результатом синтаксического обхода ДСА арифметического выражения будет инфиксный вариант записи этого выражения.
Обход "слева направо": название имеет смысл лишь в случае стандартного расположения дерева корнем кверху.
Генерация дерева синтаксического анализа
Одно и то же арифметическое выражение может быть записано тремя способами:
Инфиксный способ записи (знак операции находится между операндами):
((a / (b + c)) + (x * (y - z)))
Все арифметические операции, привычные нам со школьных лет, записываются именно таким образом.
Префиксный способ записи (знак операции находится перед операндами):
+( /(a, +(b,c)), *(x, -(y,z)))
Из знакомых всем нам функций префиксный способ записи используется, например, для sin(x), tg(x), f(x,y,z) и т.п.
Постфиксный способ записи (знак операции находится после операндов):
((a,(b,c)+ )/ ,(x,(y,z)- )* )+
Этот способ записи менее распространен, однако и с ним многим из нас приходилось сталкиваться уже в школе: примером будет n! (факториал).
Разумеется, вид дерева синтаксического анализа (ДСА)1) арифметического выражения не зависит от способа записи этого выражения (см. рис. 12.1), поскольку определяет его не форма записи, а порядок выполнения операций. Но процесс построения дерева, конечно же, зависит от способа записи выражения. Далее мы разберем все три варианта алгоритма построения ДСА.
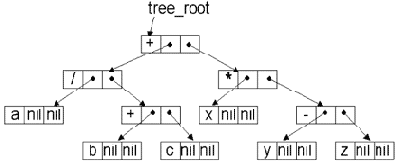
Рис. 12.1. Дерево синтаксического анализа и способ описания его элементов
type ukaz = ^tree; tree = record symbol: char; left: ukaz; right: ukaz; end;
Итеративный алгоритм
Для этого алгоритма удобно, чтобы граф был представлен списком ребер.
Массив mark, как и прежде, будет хранить номера компонент связностей, к которым принадлежат помеченные вершины графа.
Итеративный алгоритм
Алгоритм, предложенный Дейкстрой2), настолько мощнее рекурсивного алгоритма Расст-Рек, что, при тех же начальных условиях и не прикладывая дополнительных усилий, он может найти расстояние от выделенной вершины s не только до одной вершины t, но и до всех остальных вершин графа.
Итак, пусть граф задан матрицей смежности.
Линейный массив dist будет хранить длины текущих путей от вершины s до всех остальных вершин. В начале этот массив будет инициирован числами MaxLongInt, символизирующими "бесконечность". По окончании работы алгоритма в этом массиве останутся только минимальные значения длин путей, которые и являются расстояниями.
Еще один линейный массив done потребуется нам для того, чтобы хранить информацию о том, найден ли уже минимальный путь (он же расстояние) до соответствующей вершины и можно ли исключить эту вершину из дальнейшего рассмотрения.
Переменная last будет хранить номер последней помеченной вершины.
Отметим особо, что на каждом шаге Алгоритм Дейкстры находит длину кратчайшего пути до очередной вершины графа. Именно поэтому достаточно сделать ровно N-1 итераций.
Итеративный алгоритм
Для этого алгоритма удобно, чтобы граф был представлен списком ребер.
Массив mark, как и прежде, будет хранить номера компонент связностей, к которым принадлежат помеченные вершины графа.
Итеративный алгоритм
Алгоритм, предложенный Дейкстрой7), настолько мощнее рекурсивного алгоритма Расст-Рек, что, при тех же начальных условиях и не прикладывая дополнительных усилий, он может найти расстояние от выделенной вершины s не только до одной вершины t, но и до всех остальных вершин графа.
Итак, пусть граф задан матрицей смежности.
Линейный массив dist будет хранить длины текущих путей от вершины s до всех остальных вершин. В начале этот массив будет инициирован числами MaxLongInt, символизирующими "бесконечность". По окончании работы алгоритма в этом массиве останутся только минимальные значения длин путей, которые и являются расстояниями.
Еще один линейный массив done потребуется нам для того, чтобы хранить информацию о том, найден ли уже минимальный путь (он же расстояние) до соответствующей вершины и можно ли исключить эту вершину из дальнейшего рассмотрения.
Переменная last будет хранить номер последней помеченной вершины.
Отметим особо, что на каждом шаге Алгоритм Дейкстры находит длину кратчайшего пути до очередной вершины графа. Именно поэтому достаточно сделать ровно N-1 итераций.
Нахождение кратчайших путей
Задача. В заданном взвешенном связном графе найти расстояние (длину кратчайшего пути) от выделенной вершины s до вершины t. Веса всех ребер строго положительны.
Нахождение минимального каркаса
Задача. В заданном взвешенном связном графе определить множество ребер, составляющих некоторый его оптимальный каркас (например, минимальный по сумме весов входящих в него ребер).
Обходы деревьев и графов
Прежде чем приступить к изложению алгоритмов обхода, дадим пару необходимых определений.
Обход дерева - это некоторая последовательность посещения всех его вершин.
Обход графа - это обход некоторого его каркаса.
В этом разделе будут представлены только алгоритмы обхода бинарных деревьев. Большинство из них может быть с легкостью изменено для случая произвольного корневого дерева, каковым является и каркас произвольного графа.
Напомним, что структуру бинарного дерева мы описываем следующим образом:
type ukazatel = ^tree; tree = record mark: integer; left: ukazatel; right: ukazatel; end;
Итак, приступим теперь к изучению различных вариантов обхода деревьев и графов.
Обратный обход произвольного связного графа
Для простоты изложения будем считать, что граф задан матрицей смежности, которая хранится в квадратном массиве sm. Дополнительный линейный массив mark хранит информацию о последовательности обхода вершин, а массив posesh - о фактах их посещения:
procedure postorder_graph(v:byte); var i: integer; begin posesh[v]:=1; {текущая вершина v стала посещенной} for i:=1 to n do if (posesh[i]=0)and(sm[v,i]=1) {есть ребро из текущей вершины v в еще не помеченную вершину i} then postorder_graph(i); inc(k); mark[v]:=k; {текущей вершине v присвоен порядковый номер} end;
begin ... k:=0; postorder_graph(start); {вызов из тела программы} ... end.
Подсчет количества компонент связности
Задача. Определить количество компонент связности в заданном графе.
Последовательность обхода
Пометить вершину 0-го уровня (корень дерева).Пометить все вершины 1-го уровня.Пометить все вершины 2-го уровня....
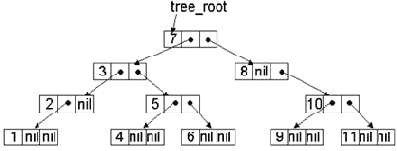
Рис. 12.4. Последовательность нумерации вершин при синтаксическом обходе дерева
Замечание: Этот алгоритм может быть естественным образом распространен и на случай произвольного корневого дерева.
Построение из инфиксной записи
Для простоты мы будем считать, что правильное арифметическое выражение подается в одной строке, без пробелов, а каждый операнд записан одной буквой. Приоритет операций определяется расставленными скобками: ими должна быть снабжена каждая операция.
Построение из постфиксной записи
Для простоты предположим, что правильное арифметическое выражение подается в одной строке, без пробелов, а каждый операнд записан одной буквой. Кроме того, снова будем считать, что из записи удалены все скобки.
Построение из префиксной записи
Для простоты предположим, что правильное арифметическое выражение подается в одной строке, без пробелов, а каждый операнд записан одной буквой. Кроме того, будем считать, что из записи удалены все скобки: это вполне допустимо, так как операция всегда предшествует своим операндам, следовательно, путаница в порядке выполнения невозможна.
Прямой обход произвольного связного графа
Для простоты изложения будем считать, что граф задан матрицей смежности, которая хранится в квадратном массиве sm. Дополнительный линейный массив mark хранит информацию о последовательности посещения вершин:
procedure preorder_graph(v: byte); var i: byte; begin k:= k+1; mark[v]:= k; {текущей вершине v присвоен порядковый номер} for i:= 1 to n do if (mark[i]=0)and(sm[v,i]=1) {есть ребро из текущей вершины v в еще не помеченную вершину i} then preorder_graph(i); end;
begin ... k:= 0; preorder_graph(start); {Вызов из тела программы} ... end.
Реализация
Мы воспользуемся здесь описанием типа данных ukaz, приведенным на рис. 12.1:
procedure infix(var p: ukaz); var c: char; begin read(c); if c = '(' then begin new(p); infix(p^.left); read(p^.symbol); {'+', '-', '*', '/'} infix(p^.right); read(c); {')'} end else begin {'a'..'z','A'..'Z'} new(p); p^.symbol:= c; p^.right:= nil; p^.left:= nil end; end;
begin ... infix(root); ... end.
Реализация
Для того чтобы упростить работу, добавим в структуру элемента дерева (см. рис. 1.12) дополнительное поле next:ukaz, которое будет служить для связки стека:
stek:= nil; while not eof(f) do begin new(p); read(f,p^.symbol); if p^.symbol in ['+','-','*','/'] then begin p^.right:= stek; p^.left:= stek^.next; p^.next:= stek^.next^.next; stek:= p end else begin p^.left:= nil; p^.right:= nil; p^.next:= stek; stek:= p end; end;
Реализация
procedure postorder(p:ukaz; k:integer); begin if p^.left<>nil then postorder(p^.left,k+1); if p^.right<>nil then postorder(p^.right,k+1) p^.mark:=k; end;
begin ... postorder(root,1); {Вызов из тела программы} ... end.
Реализация
Для простоты реализации вновь пополним структуру дерева полем next:ukaz, которое будет служить для связки очереди:
head:= root; tail:= root; k:= 0; repeat tail^.next:= head^.left; if head^.left<>nil then tail:= tail^.next; tail^.next:= head^.right; if head^.right<>nil then tail:= tail^.next; inc(k); head^.znachenie:= k; {можно write(head^.znachenie);} head:= head^.next until head = nil;
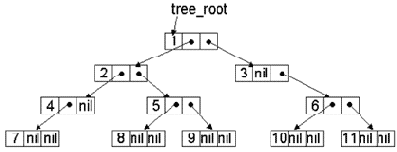
Рис. 12.5. Последовательность нумерации вершин при обходе дерева в ширину
Реализация
procedure step (v: integer); var j: integer; begin mark[v]:= k; for j:=1 to N do if (mark[j]=0)and(sm[v,j]<>0) then step(j); end;
begin ... for i:= 1 to N do mark[i]:=0; k:= 0; {номер текущей компоненты связности} for i:= 1 to N do if mark[i]=0 then begin inc(k); step(i); end; ... end.
Реализация
procedure step(v,k: byte; r: longint); var j: byte; begin if r < min then if k = N-1 then min:= r else for j:= 1 to N do if (sm[v,j]<>0)and(mark[j]=0) then begin mark[j]:= 1; step(j,k+1,r+sm[v,j]); mark[j]:= 0 end; end;
begin ... for i:= 1 to N do mark[i]:= 0; min:= MaxLongInt; for i:= 1 to N do begin mark[i]:=1; step(i,1,0); mark[i]:=0; end; writeln(min); ... end.
Для того чтобы помимо суммарного веса каркаса алгоритм также запоминал включенные в каркас ребра, необходимо добавить дополнительный квадратный массив, в котором будут храниться пометки включения ребер в каркас.
Реализация
Реализация основной части алгоритма (шаг 2) совпадает с реализацией алгоритма КомпСвяз-Итер, за исключением того, что в случаях 1, 2 и 4 необходимо ввести подсчет добавленных в каркас ребер, а внешний цикл завершить не в момент достижения конца файла, а в момент, когда счетчик добавленных ребер станет равным N-1.
Реализация
Пусть граф задан матрицей смежности sm, а массив mark хранит информацию о посещениях вершин. Напомним, что уменьшение длины пути "на возврате" совершается рекурсией автоматически, поскольку в ее заголовке использован параметр-значение, а вот аналогичное обнуление соответствующих позиций массива mark приходится делать вручную, поскольку задавать массив параметром-значением чересчур накладно:
procedure rasst(v: byte; r: longint); var i: byte; begin if v = t then if r< min then min:= r else else for i:= 1 to N do if (mark[i]=0)and(sm[v,i]<>0) then begin mark[i]:=1; rasst(i,r+sm[v,i]); mark[i]:=0 end end;
begin ... for i:= 1 to N do mark[i]:= 0; min:= MaxLongInt; mark[s]:= 1; rasst(s,0); mark[s]:= 0; ... end.
Реализация
Мы надеемся, что функцию поиска меньшего из двух целых чисел min, использованную в тексте программы, читатели смогут написать самостоятельно.
dist[s]:= 0; done[s]:= true; last:= s; for i:= 1 to N-1 do begin for x:= 1 to N do if (sm[last,x]<>0)and(not done[x]) then dist[x]:= min(dist[x],dist[last]+ sm[last,x]); min_dist:= MaxLongInt; for x:= 1 to N do if (not done[x])and(min_dist>dist[x]) then begin min_dist:= dist[x]; last:= x; end; done[last]:= true; end.
Рекурсивный алгоритм
Считаем, что граф задан матрицей смежности sm.
Каждый элемент специального линейного массива mark будет хранить номер компоненты связности, к которой принадлежит соответствующая вершина графа.
Рекурсивный алгоритм
Считаем, что граф задан матрицей смежности sm.
Каждый элемент специального линейного массива mark будет хранить номер компоненты связности, к которой принадлежит соответствующая вершина графа.
Сравнение алгоритмов КомпСвяз-Рек и КомпСвяз-Итер
В худшем случае (при полном графе) рекурсивный алгоритм, перебирая все возможные ребра, будет вынужден вызвать основную процедуру (N-1)! раз. Велика вероятность, что при достаточно большом N произойдет переполнение оперативной памяти, которое вызовет аварийную остановку программы. Кроме того, размеры квадратной матрицы смежности дают сильное ограничение на возможное количество вершин графа: не более 250 (см. лекцию 3).
Итеративный же алгоритм переберет все ребра графа, которых может быть не более чем N*(N+1)/2. В половине этих случаев возможна ситуация объединения двух компонент связности в одну, для чего потребуется еще N операций. Следовательно, общая сложность алгоритма может быть приблизительно оценена значением N3/8. Возможное количество вершин графа ограничено только максимальным размером линейного массива (32 000).